Reconocimiento de voz
El reconocimiento automático de voz (ASR, Automatic Speech Recognition) es el proceso de convertir una señal de voz, capturada por un aparato telefónico o un micrófono conectado a un PC, a información lingüística pronunciada por el locutor. La voz es la manera más natural de interacción y el ASR puede ser usado en servicios telefónicos, en interfaces hombre-máquina para entrar comandos, en máquinas de dictado, etc. La tecnología desarrollada en el LPTV se basa en HMM (Hidden Markov Models), es independiente del locutor y es capaz de tratar con lenguaje natural y voz continua. Hasta ahora, estos esfuerzos en investigación y desarrollo se han concentrado en idioma Español (ver demo). Una versión del motor de ASR desarrollado en el LPTV mantiene un servicio de telefonía celular en una Telco.
Tecnología de voz para aprendizaje de idioma

Una de las aplicaciones más importantes de tecnologías de voz tiene lugar en el área de aprendizaje de idiomas. El LPTV está liderando actualmente un proyecto en aprendizaje de Inglés como segundo idioma en Chile. ASR y estimación de parámetros de prosodia son investigadas como herramientas para evaluar la calidad de la pronunciación.
Reconocimiento de locutor

Reconocimiento de locutor es el proceso de reconocer automáticamente quién está hablando basado en la señal de voz como información biométrica. El reconocimiento de locutor se divide en identificación de locutor (SI, Speaker Identification) y en verificación de locutor (SV, Speaker Verification). SI corresponde a la tarea de asociar una voz grabada a uno entre N locutores. En consecuencia, SI es un problema de clasificación 1:N. En SV, la idea es confirmar o rechazar la identidad demandada por un locutor. Como resultado, SV es un problema 1:1. El LPTV se ha centrado en SV de texto dependiente (ver demo) y un sistema prototipo está actualmente siendo evaluado.
Procesamiento robusto de voz
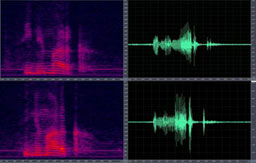
La robustez es una de las principales áreas de interés en investigación en sistemas ASR y SV. Algunos de los resultados de investigación del LPTV sobre robustez a ruido aditivo, desajuste de canal y distorsión en codificación-decodificación han sido publicados en las revistas y conferencias internacionales más importantes en el campo de tecnologías de voz.
QoS en Internet para aplicación en tiempo real
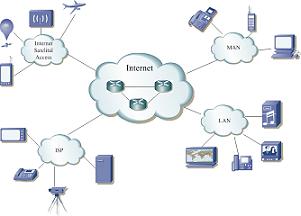
Internet se diseñó para tráfico elástico basado en TCP, el cual a su vez puede adaptar su tasa de transmisión de acuerdo a la condición de la red. No obstante, el desarrollo de diversas nuevas aplicaciones en tiempo real ha creado el problema de cómo garantizar niveles de QoS (Quality of Service, Calidad de Servicio). En el LPTV, el problema de protocolos en tiempo real se ha abordado al aplicar el algoritmo LMS para hacer que aplicaciones UDP sean TCP amigables y para reducir las discontinuidades de ancho de banda.
Transmisión de voz sobre IP
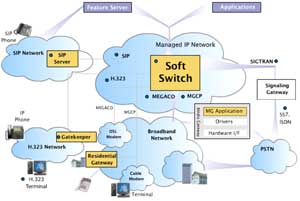
La transmisión de voz sobre Internet está afectada por pérdida de paquete y distorsión codificación-decodificación. Los problemas de precisión de ASR y evaluación subjetiva de la calidad en redes IP también se han abordado en el LPTV.
Evaluación de usabilidad de sistemas de diálogo
El concepto de usabilidad intenta medir cuán bien una interfaz puede ser usada por los usuarios a fin de obtener objetivos específicos con efectividad, eficiencia y satisfacción en un contexto de un uso especificado. En el LPTV la evaluación de usabilidad se emplea para optimizar el diseño de sistemas de diálogo a partir del punto de vista del usuario y para evaluar la confiabilidad de un servicio dado proporcionado por ASR o SV.