Speech recognition
The automatic recognition of speech (ASR, Automatic Speech Recognition) is the process of converting a speech signal, captured by a telephone apparatus or a microphone connected to a PC, to linguistic information pronounced by a speaker. Speech is the most natural manner of interaction and the ASR could be used in telephone services, in human-machine interfaces for giving commands, in dictation machines, etc. The technology developed in the LPTV, based on HMM (Hidden Markov Models), is independent of the speaker and is capable of dealing with natural language and continuous speech. To date these efforts in research and development have been concentrated on the Spanish language (see the demo). One version of the ASR engine developed in the LPTV service maintains a cell phone in a Telco.
Speech technology for language learning

One of the most important applications of speech technology takes place in the area of language learning. The LPTV is currently leading a project in learning English as a second language in Chile. ASR and parameter estimation of prosody are investigated as tools for evaluating the quality of pronunciation.
Speaker recognition

Recognition of the speaker is a process of automatically recognizing who is speaking based on the speech signal as biometric information. Speaker recognition is divided into identification of the speaker (SI, Speaker Identification) and verification of the speaker (SV, Speaker Verification). SI corresponds to the work of associating the recorded voice with one among N speakers. Consequently, SI is a problem of classification 1:N. In SV, the idea is to confirm or reject the identity claimed by a speaker. As a result, SV is a 1:1 problem. The LPTV has focused on text dependent SV (see the demo) and a prototypical system is currently being evaluated.
Robust speech processing
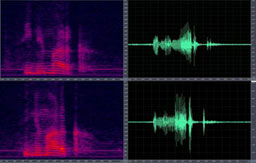
Robustness is one of the main areas of interest in researching ASR and SV systems. Some of the research results of the LPTV on robustness to additive noise, channel mismatching, and distortion in codification-decodification have been published in the most important journals and publications of international conferences in the field of speech technologies.
QoS on the Internet for real-time applications
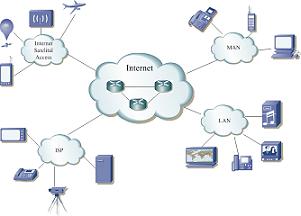
The Internet is designed for elastic traffic based on TCP, which in turn can adjust its transmission rate according to the condition of the network. However, the development of various new applications in real time has created the problem of how to guarantee QoS levels (Quality of Service). In the LPTV, the problem of real time protocols has been addressed by the application of the LMS algorithm to assure that the UDP applications will be TCP friendly and to reduce the discontinuities of wide band.
Speech transmission over IP
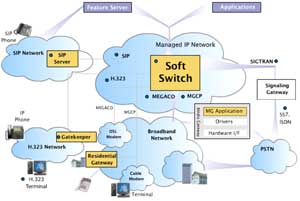
Speech transmission over the Internet is affected by packet loss and codification-decodification distortion. The problems of precision of ASR and subjective evaluation of the quality of IP networks have also been addressed in the LPTV.
Evaluation of the usability of dialogue systems
The concept of usability attempts to measure how well an interface can be utilized by users to obtain specific objectives effectively, efficiently, and with satisfaction in a specific context of use. In the LPTV the evaluation of usability has been employed to optimize the design of dialogue systems from the point of view of the user and to evaluate the reliability of a given service provided by ASR or SV.